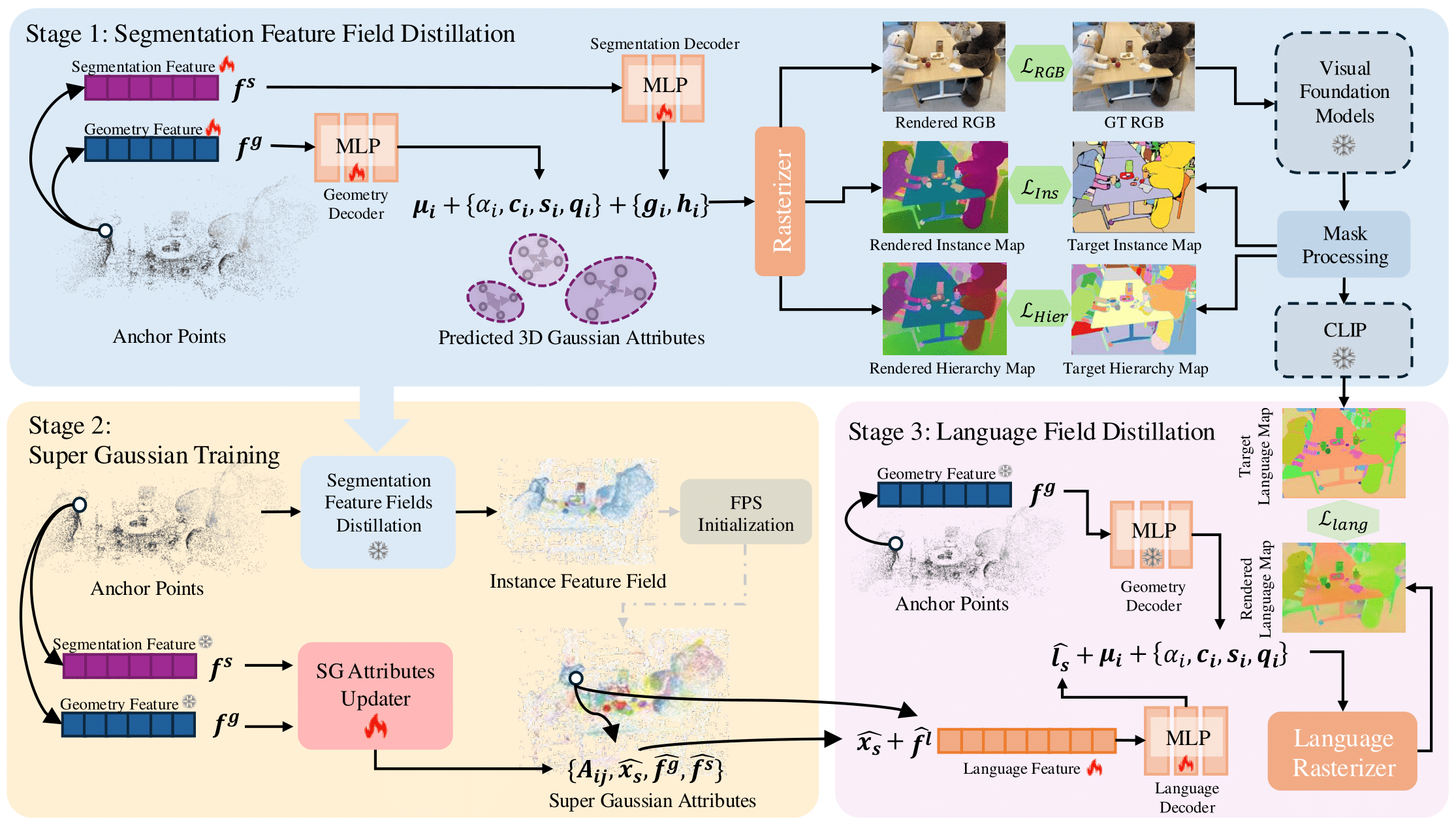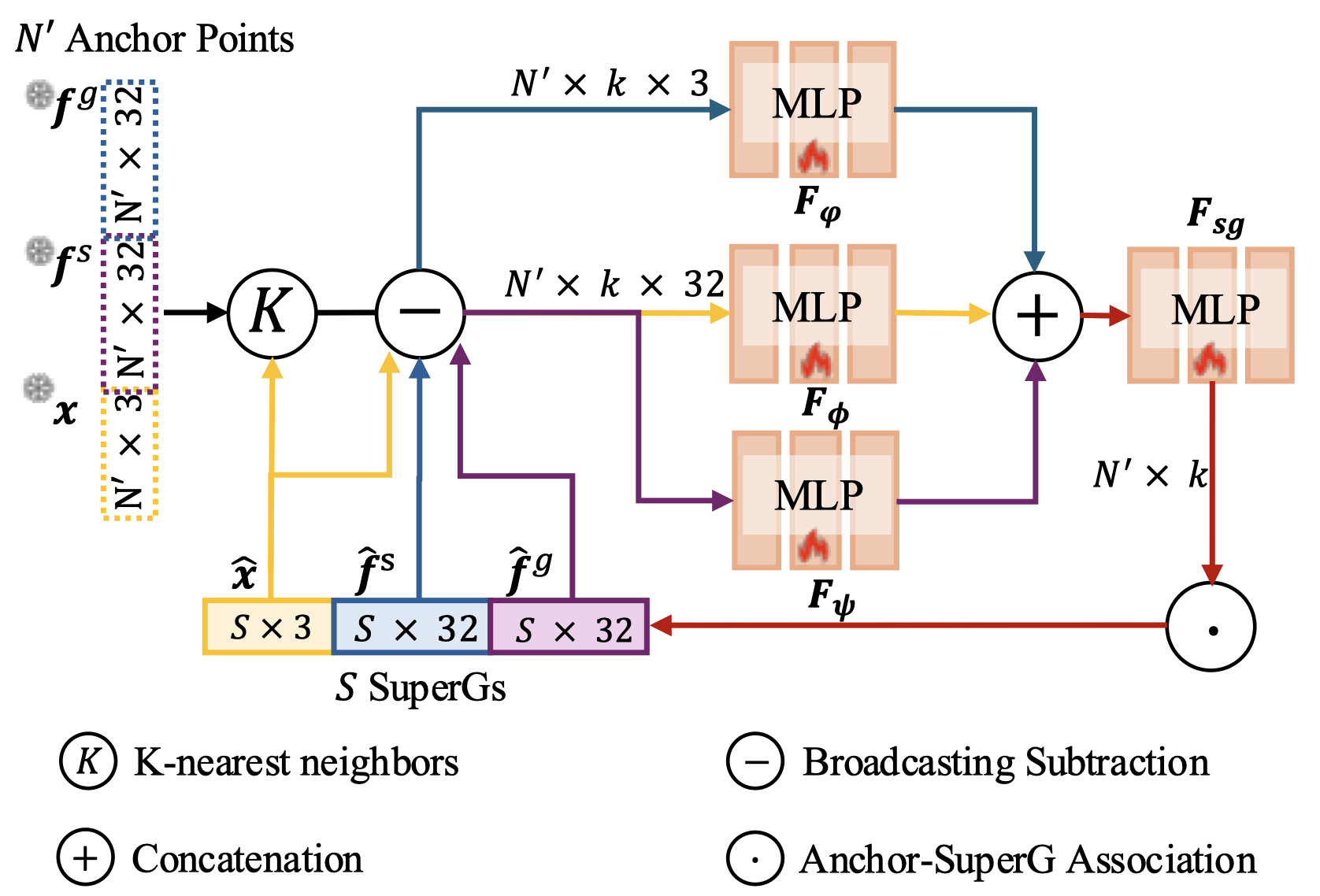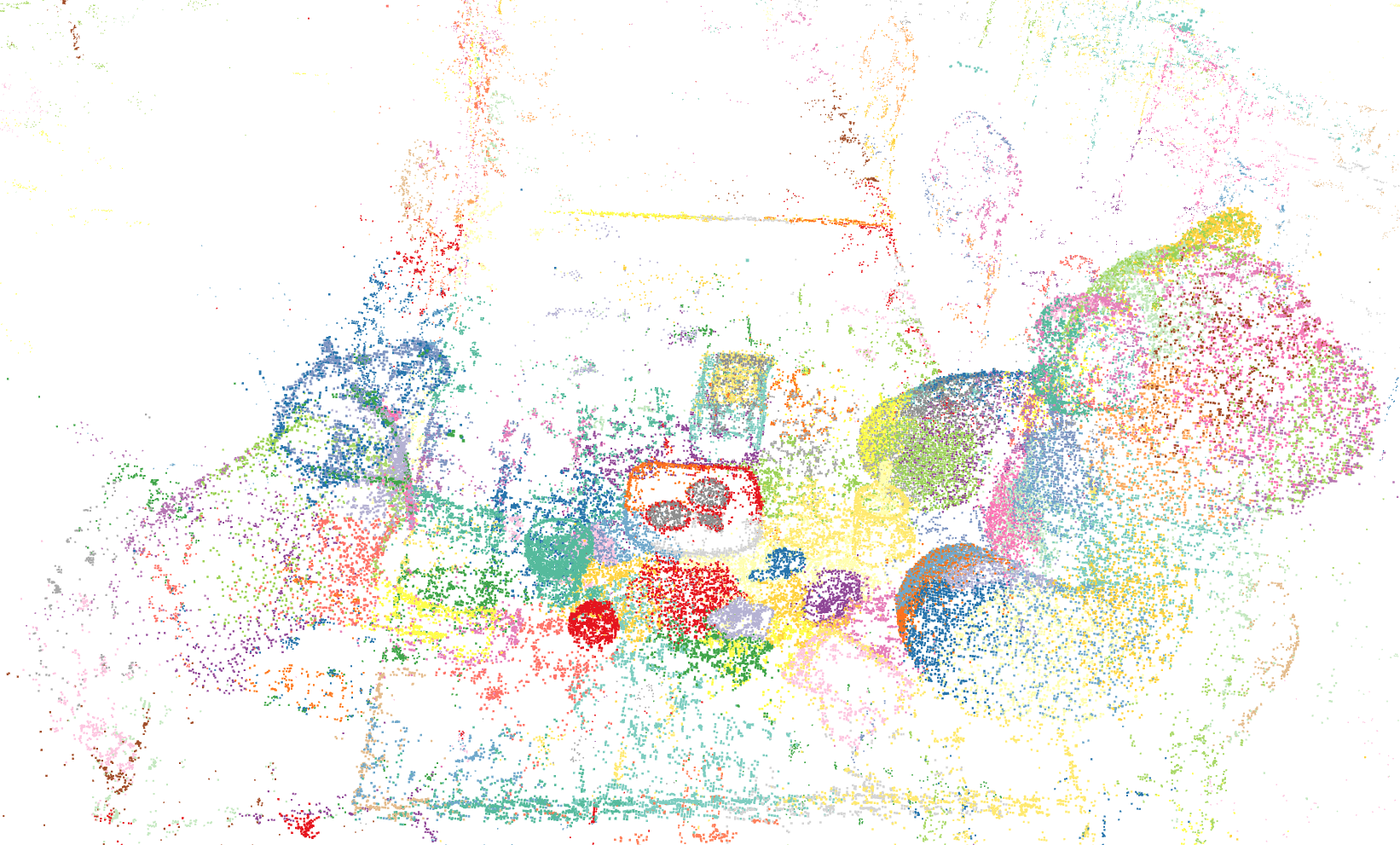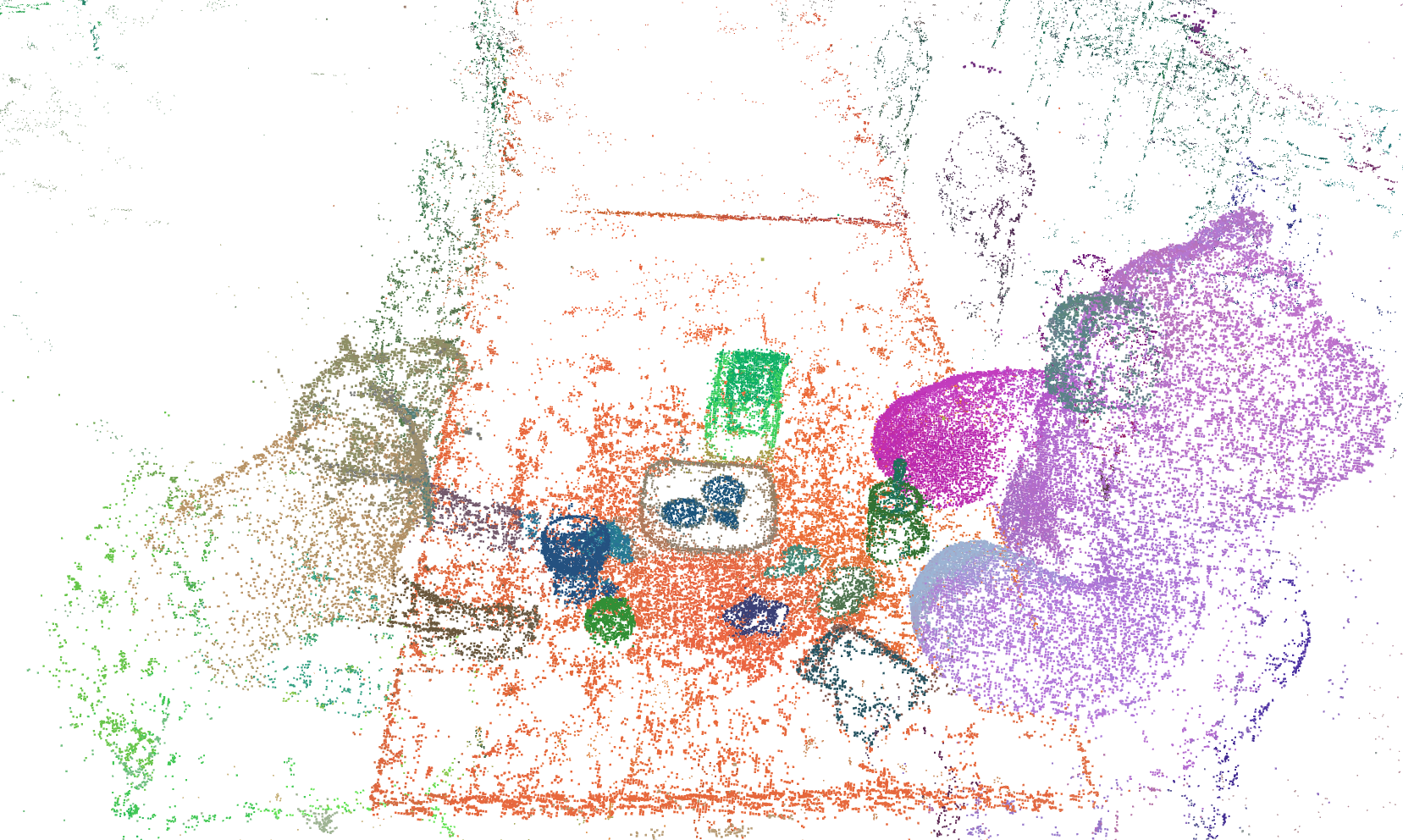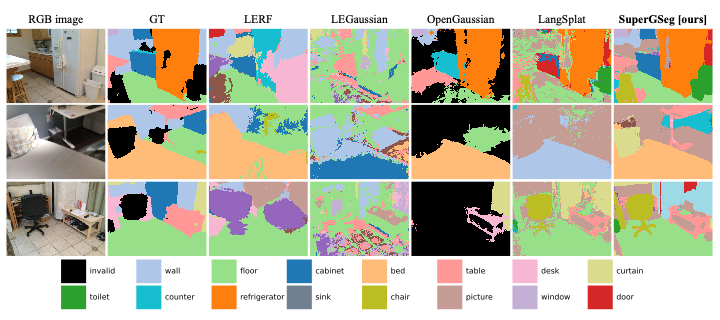
TL;DR. SuperGSeg clusters similar Gaussians into “Super-Gaussians,” merging diverse features for rich 3D scene understanding. It supports open-vocabulary semantic segmentation, promptable/promptless instance segmentation, and hierarchical segmentation.